GitHub の Projects を使っている
僕がアプリを作ったり UI を作ったりエンジニアリングのお手伝いをしているところ*1があり、そこでのタスク管理はすべて対象リポジトリへの issue ベースで行っていたのだが、それを Projects に移したらめちゃくちゃ体験が良かったので今更ながら GitHub Projects が良いという記事を書くことにした。
今北産業むけ
- label つき issue ですべて管理するのは量が多くなると大変
- issue だけでは分かりづらかった進捗が Github Projects だと可視化できて良い
- milestone と併用もいいかも
- Github Actions を発火させてもっと楽にする運用を探してる
普段の運用
提供したアプリや、lit-element で提供している UI package の調子が悪い、機能追加してほしいなど日々いろいろな要望が出てくるがそれ自体は issue で管理している。(lit-element についてはかなりつらいので移行したい)
一緒にやっている相手が長年の友達かつ機械やソフトウェアに強いという背景があったので、問題や要望が上がるたびに issue を label 付きで上げてもらって緊急度が高いものから着手したり、issue ベースで議題に上げたりしている。
ソフトウェアの保守・運用フェーズではこの isssue 運用で特に問題はなかったのだが、大きめの開発に着手したときに進捗が分かりづらかったり僕が技術的に試したいことをタスクボードとして issue 化したときにごちゃごちゃになって何がどうなってるのかわからなくなるという問題が(個人的に)発生していた。
GithubProjects 導入
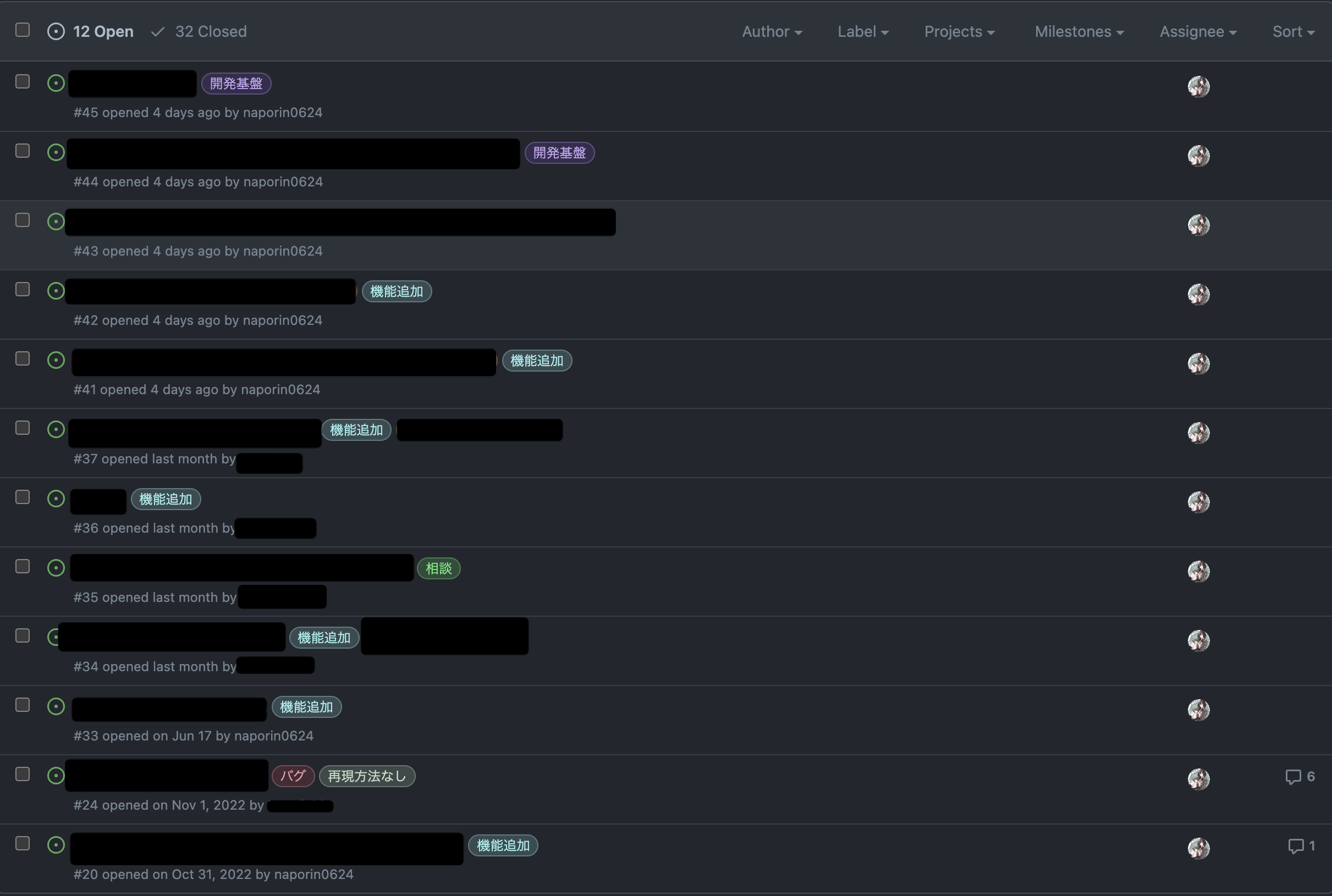
issue を GithubProjects に import するだけで使えるのでかなり簡単。表示方法も Table, Board, Roadmap の3種類選べるので見せたい UI に合わせて変えることもできる。1枚目が Table で2枚目が Board。Roadmap は使いこなせてない.....
一番良かったことは label で filter して新しい View を作ることができること。僕が技術的に試したいことを別 View だけに表示して分けることで要望と技術調査の項目を分けることができてスッキリ管理できるようになった。
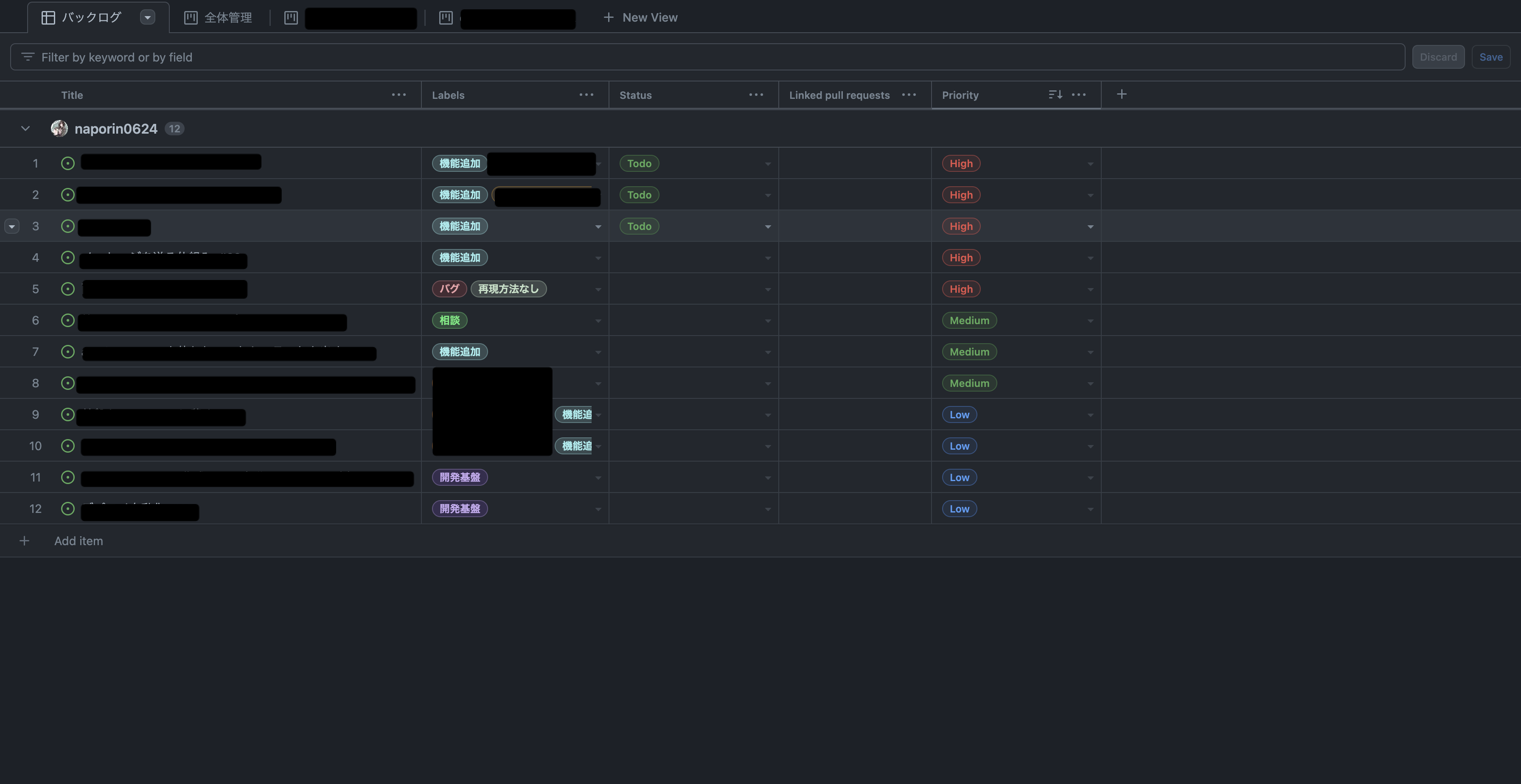
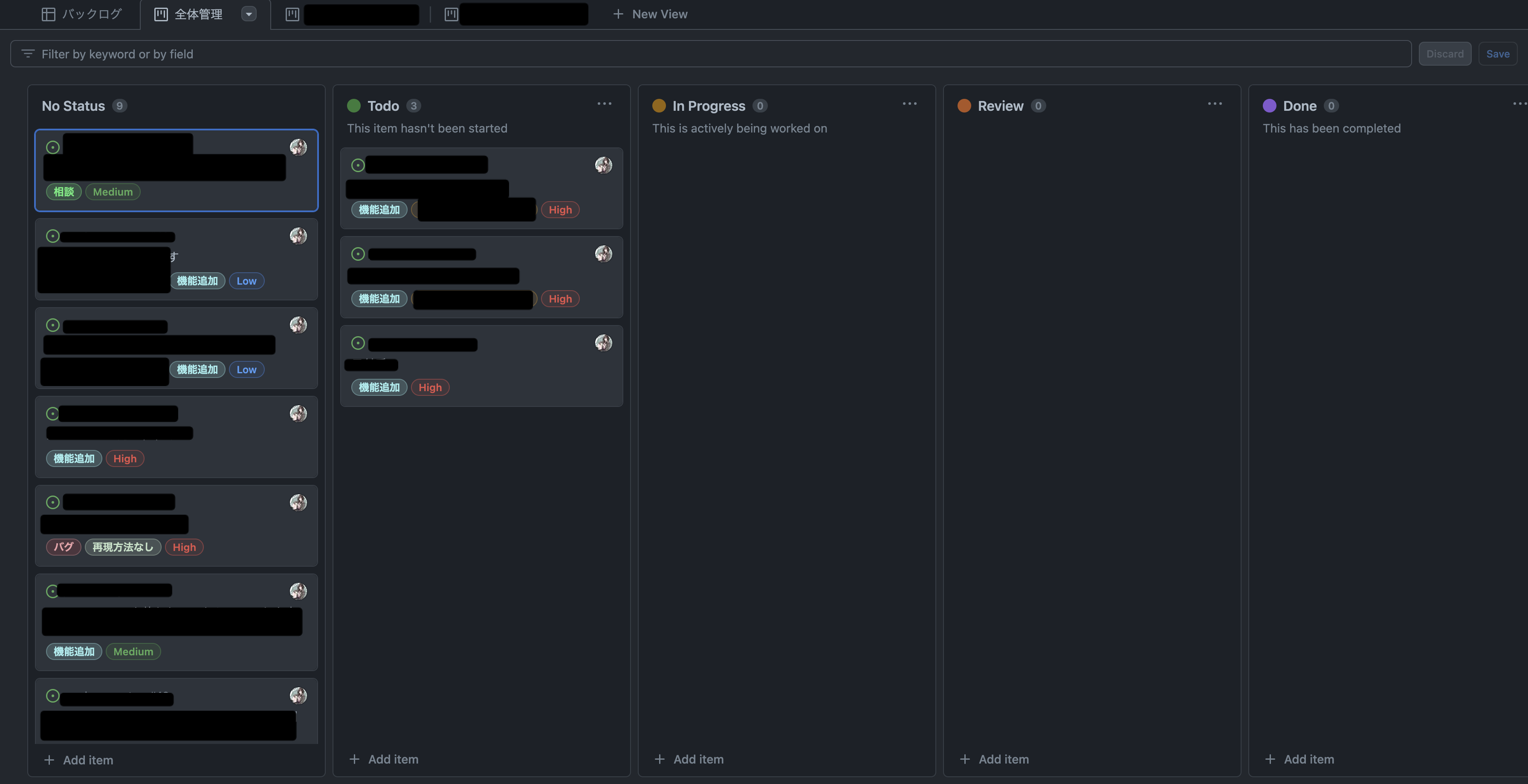
カスタムフィールドを設定することも可能でこれで priority を設定している。

GithubActions と組み合わせる
projects から issue を作ったら対象のリポジトリに issue ができるのだが、issue から projects へ issue が同期されることはないので actions を書く必要があるっぽい
GitHub で issue を作成したら自動で project に追加する方法 - ぺのめも
こういうのと組み合わせたりすると面白そうだなーって思った(custom field の Number か Date を使って PR がマージされる時間をデータとして溜め込んでおく?みたいな Metrics for issues, pull requests, and discussions - The GitHub Blog
Workers Tech Talks #1 参加レポ
Workers Tech Talks #1 に行ってきた
参加したイベントはこちら、前回参加したのが #edge_study(3月) で同じ edge worker 系の話だったので今はこの辺りの話に興味がある。
ぼく
事前知識こんな感じ
- フロントエンドやってる
- React と TypeScript が好き
- rollup で bundle size 小さくしたり、Node.js で作られたサーバーの起動時間を早くするのが好き
- 最近は cloudflare workers が安くてデプロイが早いので何かと使っている
- LP サーバーにしたり HP 置いたり、api 無理やりはやしたり、cache サーバーにしたり etc...
イベント内容
- @chimame_rt さんによる GraphQL Server on Edge
- @hiroshi3110 さんによる Gyazo の素朴な Workers
- @teckl さんによる Cloudflare Workers + R2で低コストで画像配信を移行した話/cloudflare_workers_r2_migration
- @mizchi さんによる Server Side JavaScript のためのバンドル最適化
- @codehex さんによる gRPC Client on Cloudflare Workers
@chimame_rt さんによる GraphQL Server on Edge
- cloudflare workers に GraphQL server を置いた話
- GraphQL Yoga が 2.0 から Web Standard api で動く!
- cloudrun から cloudflare workers に乗り換えた
- デプロイ速い
- コールドスタート短くなった
- cloudrun より圧倒的に安い(1/10)
- Node.js が必要な場合は別途サーバーを立てたほうがいい
- DataLoader 動かない場合があるとのこと
今日の発表資料です!ご清聴ありがとうございました!! #workers_tech / "GraphQL Server on Edge"https://t.co/5nBYl0N4w8
— ちまめ@rito (@chimame_rt) 2023年7月19日
気になったこと・感想
- cloudflare にロックインしてこれだけの恩恵を受けられるなら価値は十分だなと思った
- DurableObjects で WebSocket Server 保持してるみたいだったけど同時接続数の問題とかは起きなかったのか?
- DataLoader 動かない場合があるのはかなりつらそう(N+1 起きたときの回避策他にあるのかな?
- CPU 時間の制限は GraphQL やるうえで障害にならなかったのか?
@hiroshi3110 さんによる Gyazo の素朴な Workers
- gyazo でとった画像に直リンしたときに header がつくあれの説明だった
- cloudflare workers を 2018 年位から使っており wrangler がない時代から使っていたため、dashboard の preview で動いたら deploy という運用をしていた
- 今もしているらしい(趣がある
#workers_tech 発表資料です。https://t.co/pO6vhC1Nvi
— hiroshi (@hiroshi3110) 2023年7月19日
@teckl さんによる Cloudflare Workers + R2で低コストで画像配信を移行した話/cloudflare_workers_r2_migration
- S3 から R2 に移行した話
- かなり具体的な話 + ハマりどころまで書いてある
- Cache の話
- Cache api と KV の料金と挙動比較
- cloudflare workers は javascript が欠けるので細かい差分対応などがしやすい
- S3 から R2 に移行したことによる uri の差分修正など
- こちらもコストが大幅に下がった
さきほどの資料
— teckl (@teckl) 2023年7月19日
「Cloudflare Workers + R2で低コストで画像配信を移行した話」になります。
ありがとうございましたー
https://t.co/nJ9NrM7hHm #workers_tech
感想
- DNS 周りの話はあまり詳しくないので 7. 切り替え(NS の委任) 周りがぱっと理解できなかった。
- S3 -> R2 のインフラ移行したにもかかわらずクレームが1件で済んでいることが本当にすごいと思った
@mizchi さんによる Server Side JavaScript のためのバンドル最適化
- server side bundle の話
- wrangler は内部で
esbuild --bundleされている - bundle size がリクエストを捌く速度にも影響する
- bundle size が大きいとデプロイ直後は小さいものと比べると 2 倍くらい遅くなる
- 簡易ベンチなので参考程度とのこと
- bundle size が大きいとデプロイ直後は小さいものと比べると 2 倍くらい遅くなる
#workers_tech
— mizchi (@mizchi) 2023年7月19日
資料アップロードしました(まだいじるかも)https://t.co/fiYPTLJNJw
感想
- server side でも Bundlephobia | Size of npm dependencies を確認する時代が来たか....となった
- zod でかい....なんだ 56kb って(class method chain で作ってるしそうだよね....
- frontend だけのチューニングだと思ってたものが serverside にまで来たのは面白い
- v8 isolate が edge worker の覇権をとっちゃった今 wasm はどうなっちゃうの~?
- bundle size がでかいと deploy 直後遅くなるのは js スクリプトが v8 isolate に乗っかるまでが遅いからって理由なんだろうか?
- 明確に自分の中でわかってないところ
- v8 isolate から参照できる js の storage があってそこからの呼び出しに時間かかってる感じだろうか?
@codehex さんによる gRPC Client on Cloudflare Workers
- NOT A HOTEL はかっこいい
- cloudflare workers で gPRC を動かす話
- 設定 1つ で proxy 自体は簡単にできる
- bufbuild/protobuf-es, bufbuild/connect-es は cloudflare workers で動く!
- 多少は内部 API を組み合わせて自前で作る部分は必要
- gPRC-Edge-GateWay を作っている!
- gPRC をしゃべれない client 用に json に変換してくれるやつ
今日の資料です #workers_techhttps://t.co/VnX5ZTizwi
— へっくす (@codehex) 2023年7月19日
感想
- ブラウザで動く、Web Standard、fetch という単語は cloudfalre workers 使いにとってライブラリを見る上で重要単語になりそう
- gPRC 個人的にマイクロサービス同士がしゃべるイメージが強くあって client まで露出しないものというのがあったので gPRC-Edge-GateWay が本当に楽しみ
まとめ
- めちゃくちゃ面白かった
- #2 待ってます
- スペシャルゲストめっちゃ期待
- 主催してくださった @yusukebe さん、会場提供してくれた @classmethod さんに感謝.... :pray:
自分のホームページを大幅にリニューアルした
napochaan.com を作りました。
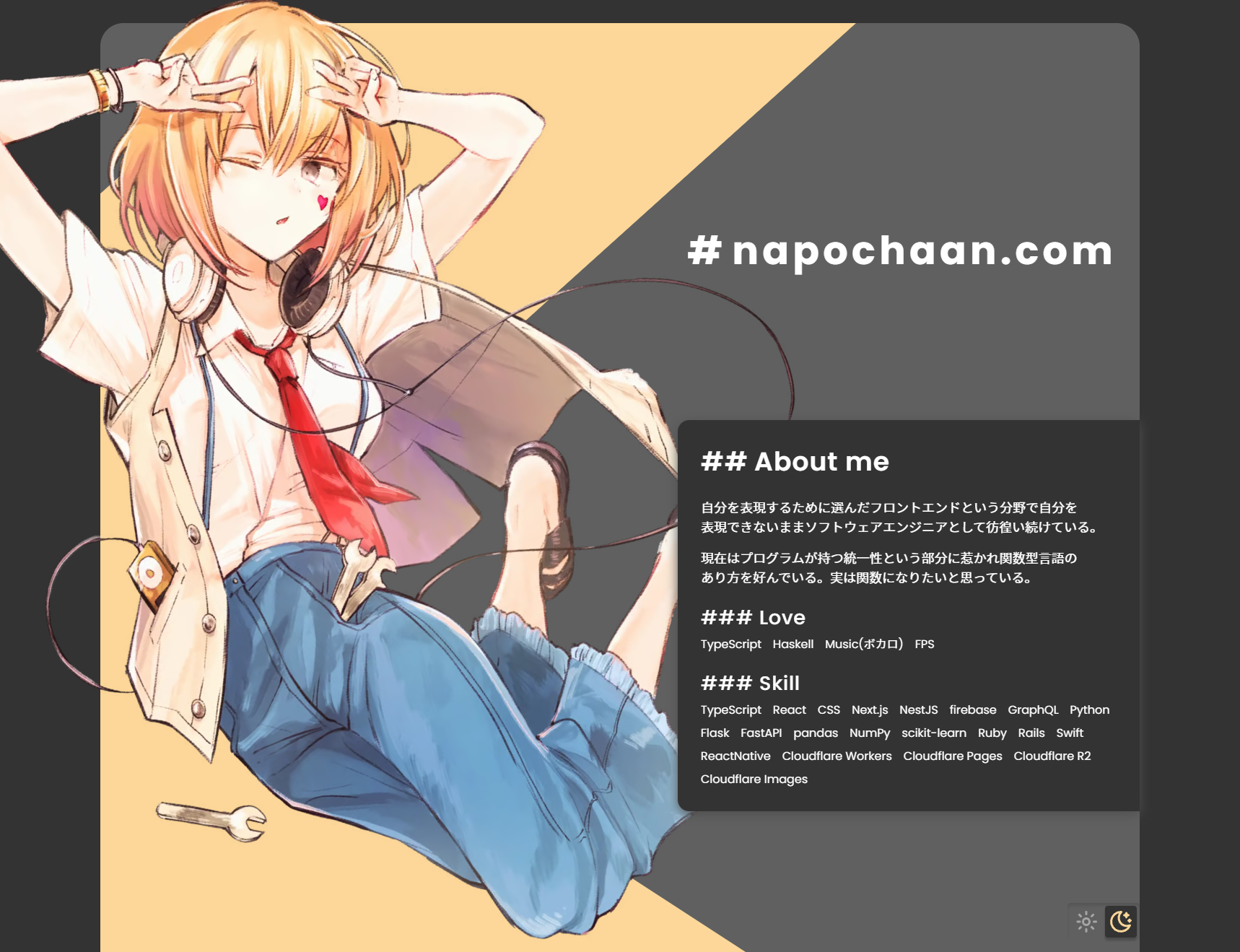
ひそなさんに書いていただいたイラストを大きく出してアニメーション多めな HP にしました。
仕様技術
- Next.js
- next-themes
- vanilla-extract
- react-spring/web
- radix-ui
- cloudflare pages
- cloudflare images
- ChatGPT
- これは技術なのか...?
- 文言は大体考えてもらった。かなり助かった。
ダークテーマ・ライトテーマ対応、a11y 対応をした
vanilla-extract と next-themes を使用してダークテーマ・ライトテーマ対応を行い、radix-ui を使用して a11y 対応をした。
ダークテーマ・ライトテーマ対応
next-themes で状態管理をしている。css variables でテーマを動的に差し替えできるようにしていて vanilla-extract の createGlobalTheme — vanilla-extract を使って実現している。
www.napochaan.com/light.css.ts at main · napolab/www.napochaan.com · GitHub www.napochaan.com/dark.css.ts at main · napolab/www.napochaan.com · GitHub
a11y 対応
最近 charcoal にコントリビューションしておりそこでは react-aria を使っているので初めはそれでやっていたのですが、next-themes と相性が悪かったのと scroll に対する hook が存在しなかったので使うのをやめた。
最終的には Primitives – Radix UI を使用した。こっちには Scroll Area – Radix UI という component が存在し react-aria でできることはカバーできていた上に SSRProvider でラップする必要がなかったためこちらに移行した。
figma を勉強できた
何もわからない状態だったが figma 自体がかなりわかりやすく、カラーパレットとコンポーネント、コンポーネントバリアントは理解できた。プラグインまわりはまだあまりよくわかってない。

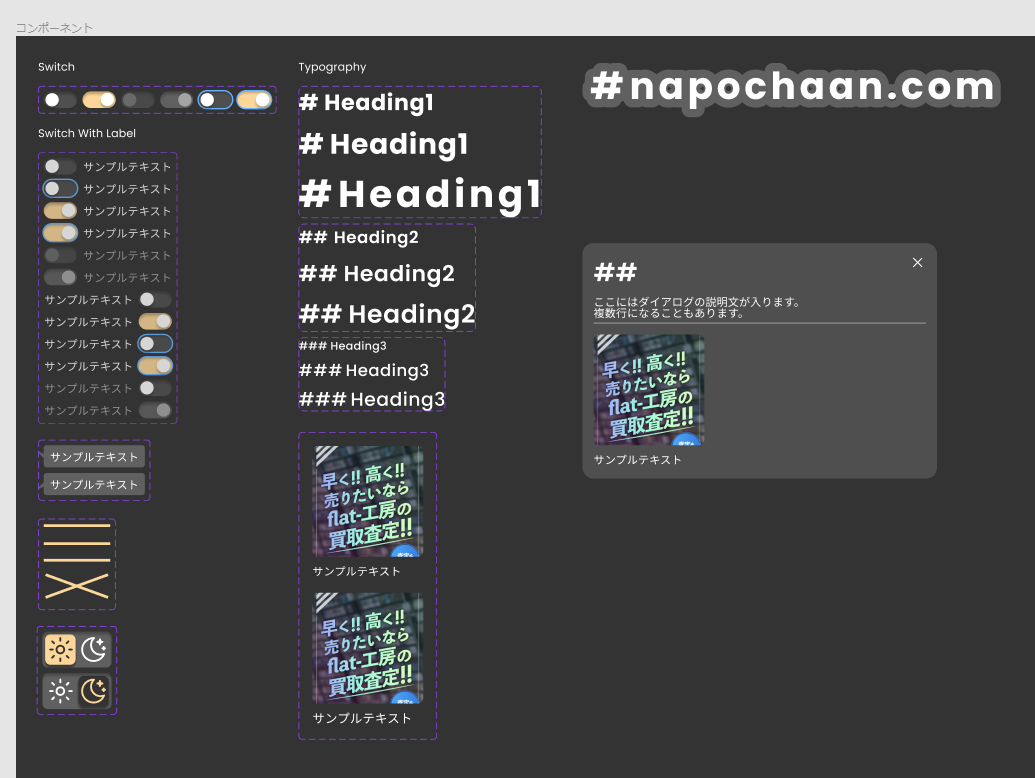
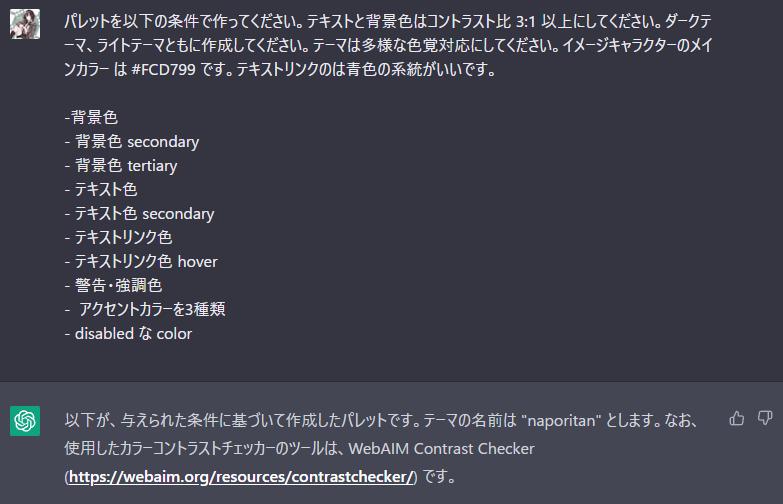
ChatGPT に文言とカラーパレットと構成を考えてもらった
テーマカラーと雰囲気を提示すると文言やパレットが生成できて便利だった。figma に起こした後微調整はしたが..... やり方が悪いのか生成するたびにパレットがちょっとづつ変わるので困った。
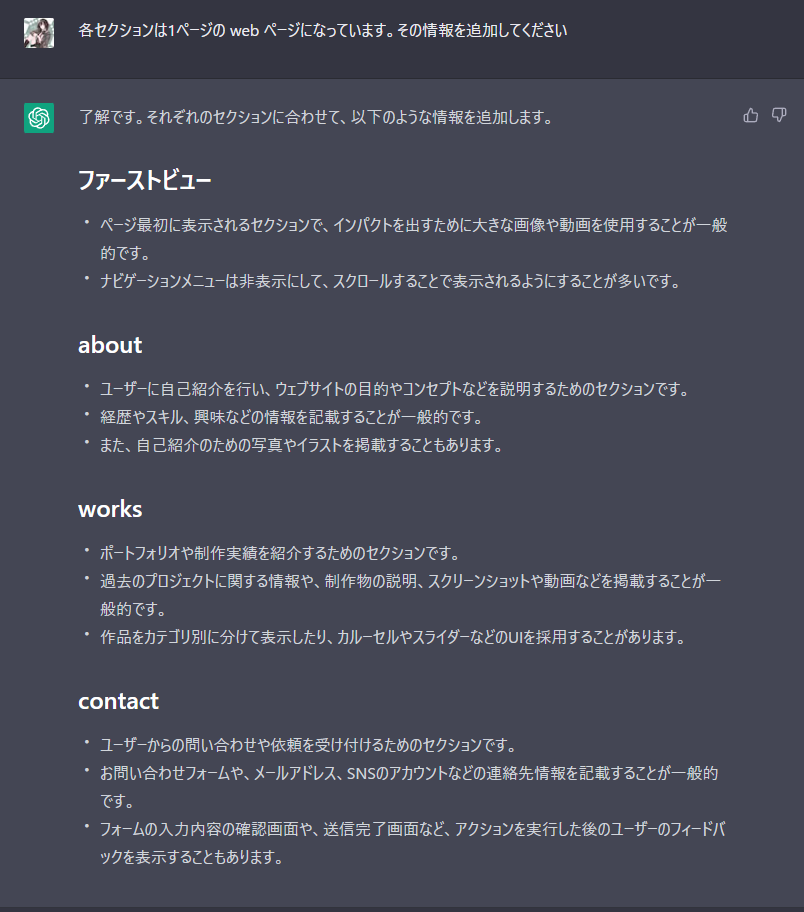
おわりに
これとは別に HP をつくろうというプロジェクトがあったときに figma がわかりません・デザインができません!というのはフロントエンドエンジニアを主戦場でやってるのにかなり良くないなぁと思ったためとりあえず全部やった。
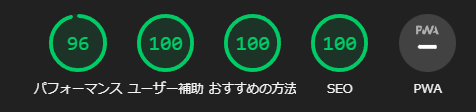
あんまりなんもしてないけど Next.js と cloudlare pages 使ったら lighthouse のスコアがめっちゃ上がったw
@apollo/client を suspense 対応させたライブラリを作った
@apollo/client でも suspense したい!
React18 がでたし、loading, data という関係ともおさらばしたい。でも @apollo/client は suspense に対応してない.....
ちょっと困ったので作りました。
以前作成したライブラリと @apollo/client を併用しています。
ApolloClient.watchQuery からデータを取得しているので refetchQueries や useQuery(gql).refetch() とも連携できてるはずです。
suspense された useQuery を体験する
前準備
yarn add @naporin0624/react-flowder rxjs yarn add graphql @apollo/client
query は長いので畳んでおきます。
import { gql, TypedDocumentNode } from "@apollo/client"; const USER_FIELDS = gql` fragment CoreUserFields on User { login name websiteUrl avatarUrl } `; const sampleQuery: SampleQuery = gql` ${USER_FIELDS} query SampleQuery { search(query: "repo:apollographql/apollo is:issue", type: ISSUE, first: 5) { issueCount nodes { ... on Issue { id number title createdAt } } } user(login: "naporin0624") { ...CoreUserFields } } `;
App.tsx
import React, { useMemo } from "react"; import { useSyncQuery, useApolloReset, } from "@naporin0624/react-flowder/apollo"; const App = () => { const data = useSyncQuery( sampleQuery, useMemo(() => ({ pollInterval: 10000, variables: {} }), []) ); const reset = useApolloReset(); return ( <div> <button onClick={reset}>reset</button> <p style={{ whiteSpace: "pre-wrap" }}>{JSON.stringify(data, null, 2)}</p> </div> ); }; export default memo(App)
index.tsx
import React, { Suspense } from "react"; import { createRoot } from "react-dom/client"; import App from "./App"; import { Provider as DatasourceProvider } from "@naporin0624/react-flowder"; import { ApolloClient, InMemoryCache, ApolloProvider } from "@apollo/client"; const token = import.meta.env.VITE_GITHUB_TOKEN; const client = new ApolloClient({ uri: "https://api.github.com/graphql", headers: { authorization: `Bearer ${token}` }, cache: new InMemoryCache(), }); createRoot(document.getElementById("root")!).render( <React.StrictMode> <ApolloProvider client={client}> <DatasourceProvider> <Suspense fallback={null}> <App /> </Suspense> </DatasourceProvider> </ApolloProvider> </React.StrictMode> );
rxjs 用の suspense ライブラリを作った
Observable から suspense でデータを取得するライブラリ作った
firestore や websocket など変化したデータを watch することができる際に有効になりそうなライブラリです。
- npm https://www.npmjs.com/package/@naporin0624/react-flowder
- github https://github.com/naporin0624/react-flowder/tree/main/packages/react-flowder
- examples https://packages-sigma.vercel.app/
なにができるか
rxjs で作られる Observable を subscribe すると流れてくる1つ目の data を suspense で取得し、その後も流れてくるデータも反映してくれるものです。 ライブラリが提供している datasouce という関数は observable を作る関数を引数に取るので filter 条件や、id、画像の small, medium, large などを後刺しできます。
firestore v9 でこのライブラリを使用する際は次のようになります。
import { Observable } from "rxjs"; import { getFirestore, collection, onSnapshot } from "firebase/firestore"; import { datasource, useDataRead } from "@naporin0624/react-flowder"; type Post = { id: string; content: string; createdAt: number; } type Filter = { // filter condition params } const db = getFirestore(); const postsCollection = collection(db(), "posts"); const posts = (filter: Filter) => new Observable<Post[]>((subscriber) => { // filter params を使って query の変更などを行う return onSnapshot(ref, (snapshot) => { const posts = snapshot.docs.map((doc) => ({ id: doc.id, ...doc.data() })); subscriber.next(posts); }, (err) => subscriber.error(err), () => subscriber.complete(), ); const postsDatasource = datasource((filter: Filter) => posts(filter)); const App = () => { const filter = useMemo<Filter>(() => ({ }), []); const data = useDataRead(postsDatasource(filter)); return <p>{JSON.stringify(data, null, 2)}</p> }
提供してる関数
datasource
Observable を生成する関数を引数にとって datasource として登録する関数です。 内部でキャッシュと対応付けるための unique な string の key を生成します。
Provider
内部的に持っているキャッシュの保持を行います。 このライブラリは僕が作っているライブラリを2つ掛け合わせて構成されているので、キャッシュの同期機構が Provider には書かれています。
useReadData
useReadData(datasource()) という形で使われ、データの Suspense による取得とデータの購読を行います。
useReset
useReset() or useReset(datasource), useReset(datasource(xxx)) という形で使われます。
useReset は関数を返し、 その関数を実行するとキャッシュが破棄され再度 Suspense されます。
引数に datasource を入れた時に破棄されるキャッシュは datasource を引数にとって得られたものだけに限定されます。
usePrefetch
useReadData を使用せずともデータを取得してキャッシュに入れたいときに使用します。loading を state として持ちたいときに便利です。
startTransition が来るまではこれで代用できるはず。
const prefetch = usePrefetch(datasource); const onClick = async () => { await prefetch(args); }
最後に
rxjs と react が非常に親和性が高いと思い込んだ結果できたライブラリです。半年くらい使用してみた結果かなり使えることが分かったのでブログを書いてみました。特に firestore との親和性が高いです。Suspense の欠点であるデータの取得が直列になってしまい、初回のレンダリングに時間がかかるという部分に関してはまだ対応できてないですが、そこにも手を入れたいと思っています。useReadDataAll 的な hook ができるはず。ぜひ、rxjs で Suspense を体験してみたいという方に使ってみてほしいです。よろしくお願いします。
内部実装では useEffect, useState を使って記述していた部分を use-sync-external-store に置き換えてみました。
自作ライブラリを use-sync-external-store を使って置き換えました。https://t.co/4XpvpYkDEF
— naporitan (@naporin24690) 2022年3月22日
置き換える前のコードhttps://t.co/3loQdonaTb
【朗報】さなのばくたん。-メチャ・ハッピー・ショー- に行ってきた 【見る処方箋】
まずは公式サイト!
チネチッタ
エロイーズカフェ
去年ぶりでしたが食べ物がうめ〜〜〜んだ... 高級カフェ.......



白熊堂
過去にかき氷をせんせえ方の日記帳ってタグだったかな?に投稿して名取に読んでもらったのが今でも忘れられないんですが、その頃から夏にはかき氷に並んででも食べに行くのが好きなので白熊どうとのコラボまじで嬉しかった!(夏じゃないが.....寒かったけどそれも一興!


ヒルバレー
初めてこういうポップコーン食べたんですけど、めっちゃハマりそう.... カラフルで可愛い上にめっちゃカリカリで美味しいんだよな..... 映画館で食べるめっちゃキャラメルでガチガチにコーティングされてしまった数個しか出会えないやつが全粒あるみたいな感じのやつ!!まじでいいものに出会えました..... ありがとう名取.....
手が写ってて申し訳ナス.....急いでた.......

ほかはまだ行けてないので....時間があるときにまた行きます.....!!!!!全制覇行くぜ!
イベント開始!
おうたパート1
【#名取爆誕 現在配信中!】
— さなのばくたん。-メチャ・ハッピー・ショー- Powered by mouse (@37bakutan) 2022年3月7日
01.青空のラプソディ
02.エッビーナースデイ
📺冒頭無料配信https://t.co/bzZEj5o7UN
🎟️配信チケットはこちらhttps://t.co/AVE12e3Fa0 pic.twitter.com/3hPUtcWPC1
- ダンスがめっちゃ良かった!キレすご〜!!前回のフラフラ体幹からは考えられないくらいめっちゃかっこよかった!
- 配信でもう一度ばくたん。みたけど、会場よりも配信の方がカメラアングルの相性もありより良く見えた〜〜まじで最高!!!
- エッビーナースデイ時の空間照明がすごくきれいで初動の勢いがガッと付いて、サイリウムの振り甲斐がありました。
- 特に「名取!」 「インターネット!」「さな!」の部分が面白かった!
ナース服パート
- ナース名取若干幼い感じというか、欲望に忠実な感じが出てて初期名取の自由奔放さというかのびのびした感じが全面に出されていて昔を思い出せた.....
- 大喜利じゃないと思ってた質問項目でもちゃんと大喜利するせんせえが多くて本当に面白かった!
出てきたスポットこの2つは本気で行きたい.... これであってるのかな?
【悲報】名取時間停止モノになってしまう
時間停止してしまった名取画面が切り替わるまでの間まじでこれになっててめちゃくちゃ楽しかった..... これもライブの醍醐味だよな〜〜〜久々の現地ライブだったけどこれこれこれ〜〜〜!!!ってなった!
時間停止モノってなんだったんだろう.....
おうたパート2
【#名取爆誕 現在配信中!】
— さなのばくたん。-メチャ・ハッピー・ショー- Powered by mouse (@37bakutan) 2022年3月7日
03.モンダイナイトリッパー!
本日初披露の楽曲です。
🎟️配信チケットはこちらhttps://t.co/AVE12e3Fa0 pic.twitter.com/rwOwMweC9T
はじめに感じたのはめっちゃこの曲サイリウムふりやす〜〜〜!!で、サビが入ることには脳内にはあらゆるとところを走り抜ける名取の映像が流れるくらい爽快感がとてつもない曲だ〜〜!!!ってなってまじで楽し〜〜〜〜この曲音ゲーで出たら無限にやっちゃう〜〜〜!!!!ってなった。sasakure.UK さんにまじで感謝.......最高の曲でした.....
王様パート
- 個性強くて笑っちゃったw
- ダジャレを言え〜〜〜のところだけ若干声がプツってたり、サイリウムで反撃したりしてていつものさなチャンネルやってて和やかだった(王の服チャンネル?
おうたパート3
【#名取爆誕 現在配信中!】
— さなのばくたん。-メチャ・ハッピー・ショー- Powered by mouse (@37bakutan) 2022年3月7日
04.だじゃれくりえぃしょん
本日初披露の楽曲です。
🎟️配信チケットはこちらhttps://t.co/AVE12e3Fa0 pic.twitter.com/IdKbnkfpOo
これは問題作ですね..... ダジャレまみれや......
ラップパートもあるし、DJイベントで名取の声をめっちゃ聴いて床になる機会も到来か?!
制服パート
制服出したのが東洋大学のイベントのあたりだったな〜って青春をしたい!というところで思い出しました..... なんかあの頃と比べるとめっちゃでかいところでイベントをするようになったなぁ..... でっかい存在になったな.....
若干王の頃の人格が残ってて笑っちゃった(拍手を.... しろ......のところ
突然名取攻略ギャルゲーが始まるも、いっつも通りプロレスしてセンブリ茶を飲まされる名取.... なんというかエモから芸人まで3人格(本人も合わせると4人格か?)いるからってやりすぎだろ......
おうたぱーと4
【#名取爆誕 現在配信中!】
— さなのばくたん。-メチャ・ハッピー・ショー- Powered by mouse (@37bakutan) 2022年3月7日
05.アマカミサマ
🎟️配信チケットはこちらhttps://t.co/AVE12e3Fa0 pic.twitter.com/LD7FGjw0ZE
アマカミサマ〜〜〜〜〜..... 何回聴ても最高ですね.....リアル会場で聴くと浄化されて泣いてしまう......
なとりパート
めっちゃこのあたりぷっつぷつでワロタw
おうたぱーと5
【#名取爆誕 現在配信中!】
— さなのばくたん。-メチャ・ハッピー・ショー- Powered by mouse (@37bakutan) 2022年3月7日
06.メチャ・ハッピー・ショー
本日初披露の楽曲です。名取さなが作詞を担当しました。
🎟️配信チケットはこちらhttps://t.co/AVE12e3Fa0 pic.twitter.com/UEiQfXBjkW
ステッキまじでかわいいな....
「見ててねせんせえ〜」あのね〜〜〜オタクは1期のOP回収大好き〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜TY(ビッグティーワイ)
「もらったものがかえしきれない」だと〜〜〜〜〜〜〜〜〜〜〜!??!?!?!!?こんな最高イベント用意しておいて何を〜!??!?!?!?!?!?!こちらこそ返しきれてないが......ありがとう.....
アンコール
拍手がはえ〜〜〜んだよwwww Vのライブはいつもそうですがアンコールの拍手が爆速でやばいwww終わって2秒位でアンコール始まる。アンコールRTAかよ......
若干のトラブルが合ったときも、サイリウムで遊ぶ人、突然連続でシャッターを切る人がいて静寂を楽しむ会場の雰囲気は最高でした

名取の犬が来きそうってなんだったんだろう....ねこちゃんせんせえでもなく犬....?イベントでは犬が襲ってくるんか?
さなのおうた
やっぱ、最後はこれだよな〜〜〜〜。もっちゃんせんせえが作ってくださった原点にして頂点..... これ最後に持ってくるのエモだし、他の歌の歌詞にも出したりしてるの愛でしょ.... 最後に来るってわかっててもまじで嬉しすぎて最高になれる.........
さいごに
今年は去年に比べ「リベンジ!」ではなく「ハッピー」に重点を置いたイベントだったな〜〜〜〜〜って終わった後に思いました。去年はイベント終了後ショック療法を受けた後の人みたいになってて余韻がすごすぎて放心してたんですが、今回は体が来る前より軽くなってたし、最近心が荒んでいたんですが赤子のようなもち肌の心になれました。(タイトル回収です。見る処方箋)
ばくたん。開催に関わったすべてのひとに感謝 🙏🙏🙏🙏🙏🙏🙏🙏
「さなのばくたん。-メチャ・ハッピー・ショー-」を作り上げてくださった皆さまです。たくさんの方に支えられてイベントが実現しました。誠にありがとうございました。 #名取爆誕 pic.twitter.com/BZOfUL2Ucx
— さなのばくたん。-メチャ・ハッピー・ショー- Powered by mouse (@37bakutan) 2022年3月7日
2022 3/8 01:39
分量少ね〜感じたことはもっとあったんですが、今回はマッジで楽しかった〜〜〜〜〜〜。それに尽きる!たのし〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜名取ありがとう〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
windows で起動するたびにディスクチェックが入るのを治す
ある日 PC を起動すると checking Systemと毎回表示され、10s 以内にキーを何かしら入力しないとディスクチェックが始まる現象に見舞われてしまい最悪に....
どうやらこの checking System が始まる原因は dirtybit が PC の不正終了によって立ってしまっていることが原因らしい。
dirtybit が立っているかどうかは powershell や command prompt で確認できる。
c: の部分はドライブ名 e: とか d: とか様々。
fsutil dirty query c:
dirtybit が立っていると次のように出力される。
Volume C: is dirty
治し方
以下の url を参考に修復。もし C ドライブに dirtybit が立っている場合はセーフモードで起動して, 2, 3 の手順を実行すると治るはず。 治らなかったらディスクが壊れている....かも....