reselectのメモ化について
reselectのメモ化がどうなってるのか知りたい
ので調べました。コード自体は100行くらいで1ファイルだけだったのでとても読みやすかったです。
reselectはreduxのためのselectorライブラリです。どうやらメモ化してくれるらしいが.....?
reselectは受け取るオブジェクトを整形する関数と結果を計算する関数を受け取って、selectorを作る関数です。
以下の例だと、state => state.itemsとstate => state.selectIdがオブジェクトを整形する関数、(items, id) => items.find(item => item.id === id)が結果を計算する関数です。
stateが変更したときどこが再計算されて、どこがメモ化されるのかを知ることでreselectの力を最大限使おうというのが本記事の意図です。
import { createSelector } from "reselect"; const state = { items: [ { id: 1, name: "hoge" }, { id: 2, name: "huga" }, { id: 3, name: "nyan" } ], selectId: 1, }; type State = typeof state; type Item = State["items"] extends Array<infer U> ? U : never; const findUser = createSelector<State, State["items"], State["selectId"], Item | undefined>( state => state.items, state => state.selectId, (items, id) => items.find(item => item.id === id) )
どこがメモ化されるのか先に言うと、最後の関数(items, id) => items.find(item => item.id === id)です。この子だけstateが変更されたときに計算がスキップされることがあります。それ以外の関数state => state.items, state => state.selectIdに関しては毎回計算されます。では実際にどのようなコードで実現されているのかを見ていきます。
reselectのコードを見ていく
createSelector
まずはcreateSelector。いつもimportして使う関数から見ていきます。これは単にcreateSelectorCreatorにdefaultMemoizeを食わせているだけのようです。何もわかりませんね。
reselect/index.js at master · reduxjs/reselect · GitHub
export const createSelector = /* #__PURE__ */ createSelectorCreator(defaultMemoize)
defaultMemoize
どうやら関数と比較関数を受け取る関数みたいです。比較関数defaultEqualityCheckは単にa === bをするだけのコードでした。気になる方は見てみてもいいかもしれませんが、ほんとにこれだけです。
areArgumentsShallowlyEqualに比較関数(equalityCheck)、前回入力された引数(lastArgs)、今回入力された引数(arguments)を食わせます。前回と今回入力された引数を比較してshallowEqualがfalseならfuncを再計算してlastResultに再代入するという感じでしょう。
argumentsに関してはjavascript組み込みなのでMDNを見るといいと思います。
reselect/index.js at master · reduxjs/reselect · GitHub
export function defaultMemoize(func, equalityCheck = defaultEqualityCheck) { let lastArgs = null let lastResult = null // we reference arguments instead of spreading them for performance reasons return function () { if (!areArgumentsShallowlyEqual(equalityCheck, lastArgs, arguments)) { // apply arguments instead of spreading for performance. lastResult = func.apply(null, arguments) } lastArgs = arguments return lastResult } }
areArgumentsShallowlyEqual
equalityCheckは比較関数、prev, nextは配列でやってくるようですね。配列の要素を総ナメして同じ値ならtrueそうでないならfalseを返すだけの関数です。
reselect/index.js at master · reduxjs/reselect · GitHub
function areArgumentsShallowlyEqual(equalityCheck, prev, next) { if (prev === null || next === null || prev.length !== next.length) { return false } // Do this in a for loop (and not a `forEach` or an `every`) so we can determine equality as fast as possible. const length = prev.length for (let i = 0; i < length; i++) { if (!equalityCheck(prev[i], next[i])) { return false } } return true }
ここまででわかったことをまとめます。
- defaultMemoizeは複数の引数を受け取る関数と比較関数(optional)を受け取る
- defaultMemoizeは複数の引数を受け取る関数を返す
こんな感じでしょうか。次に行きましょう。
createSelectorCreator
ここでのmemoizeはdefaultではdefaultMemoizeです。...memoizeOpptionsはユーザがmemoize関数を定義したときoptionを渡したときに使うものです。今回はdefaultMemoizeが使われる前提なのでいらない子として扱います。
この関数では受け取ったデータ整形用の関数と結果生成用の関数からメモ化された関数を返します。
変数名で言うとresultFuncが結果生成用の関数。dependenciesがデータ整形用の関数です。
memoizedResultFuncは結果出力関数をdefualtMemoizeでラップしただけのものなのでselectorだけを見ていきましょう。
reselect/index.js at master · reduxjs/reselect · GitHub
export function createSelectorCreator(memoize, ...memoizeOptions) { return (...funcs) => { let recomputations = 0 const resultFunc = funcs.pop() const dependencies = getDependencies(funcs) const memoizedResultFunc = memoize( function () { recomputations++ // apply arguments instead of spreading for performance. return resultFunc.apply(null, arguments) }, ...memoizeOptions ) // If a selector is called with the exact same arguments we don't need to traverse our dependencies again. const selector = memoize(function () { const params = [] const length = dependencies.length for (let i = 0; i < length; i++) { // apply arguments instead of spreading and mutate a local list of params for performance. params.push(dependencies[i].apply(null, arguments)) } // apply arguments instead of spreading for performance. return memoizedResultFunc.apply(null, params) }) selector.resultFunc = resultFunc selector.dependencies = dependencies selector.recomputations = () => recomputations selector.resetRecomputations = () => recomputations = 0 return selector } }
selector
このselectorはcreateSelector()の返り値そのものです。なのでこの子が実データ(一番はじめの例でいうとstate)を受け取ります。
与えられた実データをargumetns経由で取り出します。それをデータ整形用の関数(dependencies)に食わせます。このときdependenciesの関数たちに引数を適用する計算はselector実行時に毎回呼ばれるのでデータ整形用の関数はコストの小さい関数を置いておくのがいいでしょう。
こうして得られた配列paramsをmemoizedResultFuncに与えます。paramsの結果が前回と同じであれば計算をスキップし、前回の結果を返します。reselectにおいてここだけが計算が省略される部分というわけでした。
reselect/index.js at master · reduxjs/reselect · GitHub
const selector = memoize(function () { const params = [] const length = dependencies.length for (let i = 0; i < length; i++) { // apply arguments instead of spreading and mutate a local list of params for performance. params.push(dependencies[i].apply(null, arguments)) } // apply arguments instead of spreading for performance. return memoizedResultFunc.apply(null, params) })
まとめ
- 計算がスキップされるのは
createSelectorで渡す引数のうち最後の関数だけ! - 最後の関数以外は毎回計算される
この2つだけわかれば十分すぎるくらいです。reselect完全に理解した!ですね!
reselectメモ化してくれることは知っていたのですが、どこメモ化されるのか全くわからずuseSelectorに食わせる関数を作ってくれる君程度にしか思ってなかったのでちゃんと理解できてよかったです。
あとarguments。存在を知らなかったので突然定義してないやつが出てきた!?!?!?と凄い驚きました。
おわりです。ありがとうございました。
手首を回したら驚かれた話
最近あまりにも腰が痛かったり、肩首が終わってるので整体に行き始めました。
手首回した時に
整体師 < すごいですね〜これ
と言われてしまい
僕 < え、何がですか?
って聞いたところ
整体師 < 普通こんなに手首ってパキパキ言わないんですよ…
って言われてしまいめちゃくちゃ驚きました!!
手首って回すとパキパキ音が鳴って痛いのは全人類そうなると思ってました………
運動しないし、ほぼ座ったままの生活、良くないですね…
日記でした
TypeScriptのTemplateStringTypesでorder関数
Array.prototype.sortにわたすorder関数の型定義
Playgroundはこちらいろいろ触ってみてください。
文章
sortにわたすorder関数を配列の要素がネストしているオブジェクトだったとき即時関数で書かなきゃいけないのが辛いというのが根底にある気持ちです。
僕が求めるorder関数は、型とsortしたいkey(string)をわたしてdesc, ascだけ決めればokみたいなインターフェースでした。
TypeScriptだと配列の要素がネストしているオブジェクトのときkeyがstringでかけないな〜というのが悩みでしたが、TemplateStringTypesでそれが解決できたので作って見ました。order関数がそれに当たります。
optionsの中にあるadapterというのはsortの方法をカスタマイズするためのオプション引数です。
type NestColumn<T, U extends string> = T extends { [key: string]: unknown } ? `${U}.${Columns<T>}` : U; type Columns<T extends { [key: string]: unknown }> = { [K in keyof T]: K extends string ? NestColumn<T[K], K> : never }[keyof T] type Split<T extends string, D extends string> = T extends `${infer Head}${D}${infer Tail}` ? [Head, ...Split<Tail, D>] : [T]; type O<T, C extends unknown[]> = T extends { [key: string]: unknown } ? Target<T, C> : never type Target<T extends { [key: string]: unknown }, C extends unknown[]> = { [K in keyof T]: C extends [infer Head, ...(infer Tail)] ? K extends Head ? Tail extends [unknown, ...(infer _Tail1)] ? O<T[K], Tail> // Tailが残っているとき : T[K] // 解析終了 : never // 対象のkeyじゃないとき : never // そもそもCが空のとき }[keyof T] type Options<T extends { [key: string]: unknown }, C extends unknown[], S extends string> = { adapter?: (t1: Target<T, C>, t2: Target<T, C>, sort: S) => number } function order<T extends { [key: string]: unknown }, C extends Columns<T>>( columns: C, sort: "asc" | "desc", options?: Options<T, Split<C, ".">, "asc" | "desc">) { const keys = columns.split(".") as Split<C, "."> return (obj1: T, obj2: T) => { let t1: any = obj1; let t2: any = obj2; keys.forEach(key => { t1 = t1[key] t2 = t2[key] }) if (options?.adapter) return options.adapter(t1, t2, sort) if (sort === "asc") return t1 > t2 ? 1 : -1 return t1 < t2 ? 1 : -1 } }
最後に
こういうのでもライブラリ化していいのかな〜オレオレ型定義ライブラリ作りてぇ〜〜〜〜〜
anyを使ってしまいました。懺悔します。
let t1: any = obj1; let t2: any = obj2;
以上です。
インターネットとリアルが混じって恥ずかしくなる瞬間
ハンドルネームは名前っぽいほうがええ!
僕のハンドルネールはNaporitanとかなぽりたんでやっています。
会社では「なぽりくん」って呼ばれています。インターネットでは「なぽ」ってよばれてることがおおいです。
社内で初めて合う人とかに軽く自己紹介的なことするじゃないですか、
〇〇です。こんちには。 今日はこれこれするためにやってきました
みたいなこと言うじゃないですか......
その時毎回、「本名じゃないんですが」とか「社内ではこう呼ばれてて」っていうprefixをつける必要があるんですよね。
なんかこう・・・・・ちょっと恥ずかしい!!!!
それもこれも、「なぽりたん」とかいう明らかに食べ物名をハンドルネームにしてるからですね・・・・
ハンドルネームは名前っぽい名前にしてないと初対面に自己紹介するときにちょっと恥ずかしいよって話でした。
flowからTypeScriptへ移行するときこんな感じでやればいいんじゃないかという案
flowからTypeScriptへ
- ts-migrateをつかう
- 新しく作るページをts化して参照するモジュールにd.tsをかく
ts-migrateを使う
これで倒せるなら最高だが、テストを書いてないと主要なページすべてを動作確認する必要がありそう。ASTで機械的に変更すると言っても何らかのバグを踏み抜いてでかいバグをプロダクションで起こすのはまずい。
e2eテスト、単体テスト、QAを毎回やってるチームなら行けそう。時間が捻出できればだが......
新しいページをts化参照するモジュールにd.tsをかく
とりあえず始められそうでいいんじゃないかなと思った手法。ts化が完了したらd.tsが書いてあるファイルを触った人がjs, d.tsをけしてtsファイルになおしていく感じ。
ただd.tsを書いた後に、古いページを改修することになってd.tsを書いたjsをいじることになったら二度手間感ある....。古いページに手を入れるときにそのページもts化してね〜ってやったときのコストと相談だよな〜て感じもする。
最後に
2番目のほうが受け入れられやすい気がする。どうですか?ASTでバコって変換する系はts-migrate最強感ありますよね〜
flowに対する気持ち
flowのextensionをVSCodeに入れるととんでもなく重くなるんですよね。git switchするとVSCode固まる......。(解決策知っている人いたら教えて下さい)
TypeScriptはhttps://github.com/microsoft/TypeScriptでコード読んでる分には全然重くなかったし、ホバーして推論結果出すのも爆速だった気がする。
flowはanyに対して許容的というかimport type { Hoge } from "huga"ってやったときにhugaの型定義がinstallされて無くてもHogeがanyとして扱われるだけで何も怒らないので、そこはやだな〜って思います。
ひたすら文献が少ない。これに尽きる....utility typeとplaygroundとにらめっこしてflowのこれはTypeScriptで書くんだよ〜みたいな謎技術を得てしまった。
もしflowからTypeScriptに変換する際に型定義で困ったときは声かけてください。めちゃくちゃ複雑じゃない限り解けると思います。
input rangeのcssをカスタマイズしたときに進んだ量の色が消える問題
<input type="range" />のcss`-webkit-slider-runnable-trackで困った話
こいつの話です
こいつにcssを当てる際-webkit-slider-runnable-trackを使うと思うんですが(firefoxもありますよねmozなんとか)、backgroundの色変えたくなるじゃないですか・・・・・・・
こんなcss書くと
<style> input[range]::-webkit-slider-runnable-track { background: red; </style> <input type="range" />
こうなるんす........

お前の青い部分の色だけ変わってくれればよかったんだけどな........ってなったんですが
webkitのprogressだけの色を変えるcssは非標準らしいんですね...... developer.mozilla.org
なので擬似的に再現する必要がありますと....僕はReactで次のように考えました
linear-gradient使ったら行けるんじゃねって
import React, { useState } from "react"; import styled from "styled-components"; export default function App() { const [value, setValue] = useState(0); return <Range value={value} onChange={(e) => setValue(parseInt(e.target.value, 10))} />; } const Range = styled.input.attrs({ type: "range", min: 0, max: 100 })<{ value: number }>` &::-webkit-slider-runnable-track { background: red; background: linear-gradient(to right, red ${(props) => props.value}%, white ${(props) => props.value}% 100%); } `;
ぽいのができました。もっといいやり方あったら教えて下さい:pray:

normalizrの型定義を書いた
Normalizrの型定義を(制約付きで)書いた
normalizrのhelper型です。こうなってくれているといいなぁと思って書きました。
読むのめんどくさいよ〜って人はサンプルを用意したのでcodesandboxか手元の環境でガチャガチャいじってみてください https://github.com/naporin0624/normalizr_ts
Normalizrというライブラリについて
normalizrというライブラリがあります。これはobjectをユーザが定義した構造(normalizrはこれをschemaとよんでいる)に従って分解できるライブラリでRedux公式ドキュメントに使うといいよって書かれてたりします。Normalizing State Shape | Redux
何ができるか
GitHubに大まかな挙動・APIドキュメントが存在しているので食わせるデータと結果だけを書きます。
食わせるデータ
{ "id": "123", "author": { "id": "1", "name": "Paul" }, "title": "My awesome blog post", "comments": [ { "id": "324", "commenter": { "id": "2", "name": "Nicole" } } ] }
ユーザがschemaを定義します。
import { normalize, schema } from 'normalizr'; // Define a users schema const user = new schema.Entity('users'); // Define your comments schema const comment = new schema.Entity('comments', { commenter: user }); // Define your article const article = new schema.Entity('articles', { author: user, comments: [comment] }); const normalizedData = normalize(originalData, article);
normalizedDataの結果がこうなります。
{ result: "123", entities: { "articles": { "123": { id: "123", author: "1", title: "My awesome blog post", comments: [ "324" ] } }, "users": { "1": { "id": "1", "name": "Paul" }, "2": { "id": "2", "name": "Nicole" } }, "comments": { "324": { id: "324", "commenter": "2" } } } }
やってくるjsonをユーザが定義したschemaごとに分解してentities配下に置かれます。resultをnormalizrにあるdenormalizeに食わせることでもとのjsonを得ることができるというものです。ちなみにdenormalizeは次のように記述します。
import { denormalize } from 'normalizr'; const denormalizedData = denormalize(result, article, entities /* jsonのentitiesを入れる */ );
かなり柔軟にschemaは意義できます。normalizr/api.md at master · paularmstrong/normalizr · GitHub
TypeScriptの型定義を見てみる
normalizr/index.d.ts at master · paularmstrong/normalizr · GitHub
export function normalize<T = any, E = { [key:string]: { [key:string]: T } | undefined}, R = any>( data: any, schema: Schema<T> ): NormalizedSchema<E, R>; export function denormalize( input: any, schema: Schema, entities: any ): any;
かなりanyだらけになっていてnormalizeするとき投入したdataに対してどのschemaがマッチするのかわからないです。またdenormalizeも同じで投入するinputに対してどのschemaを入れればよいのかわからない状態になっています。かなり柔軟にschemaを定義できるようにした代償なのかなと思っている。(僕も柔軟なschemaを維持したまま型定義を書こうとして辛くなってやめた過去もあります。)なので今回はschemaの作り方に制約をもたせて型定義を書いていきます。
目指すところ
- entity型に含まれるentityを探し出して
schema.Entityの第2引数に必要なschema.Entityの組が推論される normalizeの第1引数に入れた型からほしいschema.Entityを推論するdenormalizeのReturnTypeを推論する
normalizrのschemaに制約をもたせる
A, B, Cはそれぞれの対応関係を型定義で表したものです。これからこの型定義のことをentityといいます。
Cの型を持つjsonが飛んできてnormalizeに食わせるとA, B, Cをentities配下に持ち, Cのidをresultに持つオブジェクトが返ってくるようなイメージです。
型定義を作るにあたってentityに制約をもたせます。 1. entityは必ずidを持つ 2. entityの持つプロパティにはentity同士のunion型を許容しない - C型のfのような形は許可しません - c, d, eのような形は問題ないです 3. entityの持つプロパティにはentityを含むPropertySignatureを許容しない - C型のgのような形は許可しません
type A = { id: string | number; // required hoge: string; huga: number; } type B = { id: string | number; // required cat: string[]; dog: string[]; } type C = { id: string | number; // required a: number; // ok b: number | string; // ok c: A; // ok d: A[]; // ok e: A | null; // ok f: A | B; // ng g: { a: A } // ng }
schemaに制約をもたせてnormalizrの型を書いてみる
実装するにあたりこの型はentityであるということを示すためにBaseEntityという型をつくりentityを作るときはこれをマージすることにしました。
type IUser = { name: string; address: string; phoneNumber: number; } & BaseEntity;
構造を定義するschemaの型定義をかく
RelatedEntitiesでGenericで渡されてきたentityの中で使われているentityを探し出します。探し出されたrelatedEntitiesがそのままnew schema.Entityの第2引数に渡るのでentityの型からnormalizrに渡すschemaを決定することができます。
import { schema } from "normalizr"; export const createEntity = <T extends BaseEntity>( entityName: string, relatedEntities: RelatedEntities<T>, ): schema.Entity<T> => new schema.Entity<T>(entityName, relatedEntities);
RelatedEntities型
RelatedEntities型はGenericを受け入れます。Find型により、受け入れたTを1層だけmapped typeで走破してBaseEntityが持つkeyを両方持っているものをentityとみなして新たに型を作り上げていきます。BaseEntityは型情報としては持っているが値としては入れられることもないし、認識することもない_$entityというプロパティを持っています。これのおかげでidだけをプロパティとしてもっていてもentityとして検知されないようにしています。つまり、BaseEntityをマージしたものだけをentityとしてすく上げることができるようになります。
すくい上げられたentityだけを含む型に対してnormalizrのschema.Entity型を付与していきます。
import { schema } from "normalizr"; type BaseEntity = { id: string; _$entity?: unknown; }; type NestArray<T> = T | Array<NestArray<T>>; type Flatten<T extends NestArray<unknown>> = T extends NestArray<infer I> ? I : never; type BaseType<T> = Exclude<Flatten<T>, null | undefined>; type FindKeys<T> = { [K in keyof T]: keyof BaseEntity extends keyof BaseType<T[K]> ? K : never }[keyof T]; type Schema<T> = T extends Array<infer U> ? [Schema<U>] : schema.Entity<T>; type DictSchema<T extends { [key: string]: unknown }> = { [K in keyof T]: Schema<Exclude<T[K], undefined | null>> }; type Find<T> = { [K in FindKeys<T>]: T[K] }; type RelatedEntities<T extends { [key: string]: unknown }> = DictSchema<Find<T>>;
normalizeの型を書く
normalizeの型は割と簡単です。受け入れるTに対応したschemaを待ち受ければよいだけです。
返り値はresultとentitiesがありますが、entitiesは今回かんたん化のためにユーザが定義したentityをimportしてEntitiesという型を作っています。(ここも推論できるのがより良いですが、実現できなかったのでこのようにしました:sob:)
EntitiesのなかにあるNormalizedEntity型はGenericで渡されるentityの中からentityを探し出してstringまたは, stringの配列にしてくれるものです。entityを含むentityをnormalizeするとentityがあった部分には他のentityへの参照であるidが格納されているからです。(normalizedDataを見るとわかると思います)
import { schema, normalize, NormalizedSchema } from "normalizr"; type Schema<T> = T extends Array<infer U> ? [Schema<U>] : schema.Entity<T>; type ArrayToString<T> = T extends Array<infer U> ? Array<ArrayToString<U>> : string; type NormalizedEntity<T extends { [key: string]: unknown }> = { [K in keyof T]: K extends keyof Find<T> ? ArrayToString<T[K]> : T[K]; }; type Entities = Partial<{ // 定義したentity型をimportしてnormalizeされたときに排出されるentitiesの型とする users: { [key: string]: NormalizedEntity<IUser> }; groups: { [key: string]: NormalizedEntity<IGroup> }; addresses: { [key: string]: NormalizedEntity<IAddress> }; }> type Result<T> = T extends Array<infer U> ? Array<Result<U>> : string; export const normalizer = <T>(data: T, schema: Schema<T>): NormalizedSchema<Entities, Result<T>> => normalize<T, Entities, Result<T>>(data, schema);
denormalizeの型を書く
denoramlizeはdata(単一のidもしくはidの配列)とschema(dataが分解される前の構造情報)とentitiesを渡せばよいです。
dataが単一ならschemaも単一で, dataが配列ならschemaも配列で与えるように型を書いていきます。dataからはdenormalizeのReturnTypeを推論することはできないので, 渡されたschemaからentityの型をGenericを用いて取り出します。Genericで取り出されたentityの型Sを渡されたdataの型に合わせて整形し直します。
denoamlizeしたときに第3引数のentitiesに必要なデータがないときdataが単一ならundefined, 配列なら[]が返されるのでDenormalized型を使ってそれを表現します。
import { schema, denormalize } from "normalizr"; type NestArray<T> = T | Array<NestArray<T>>; type Entity<D, T> = D extends Array<infer U> ? [Entity<U, T>] : schema.Entity<T>; type Denormalized<D, S> = D extends Array<infer U> ? Array<Denormalized<U, S>> : S | undefined; export const denormalizer = <D extends NestArray<string>, S, T extends Entities>( data: D, schema: Entity<D, S>, entities: T, ): Denormalized<D, S> => denormalize(data, schema, entities);
使ってみる
こちらにサンプルコードをpushしたのでcheckoutすればすぐ使えます。GitHub - naporin0624/normalizr_ts codesandboxにも上げましたempty-glade-xxys6 - CodeSandbox
createEntity
src/entities/group.tsをみてください
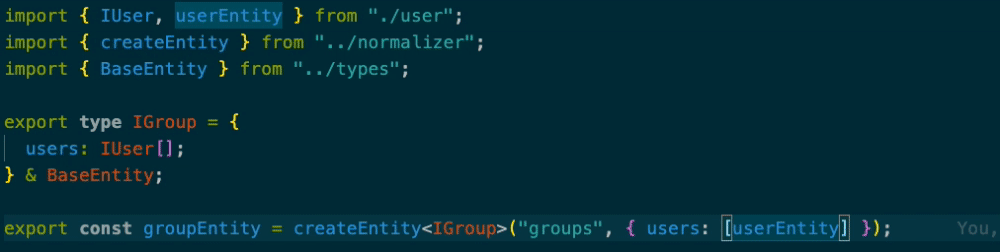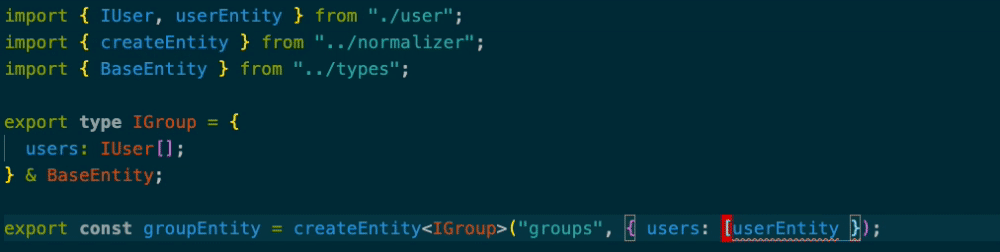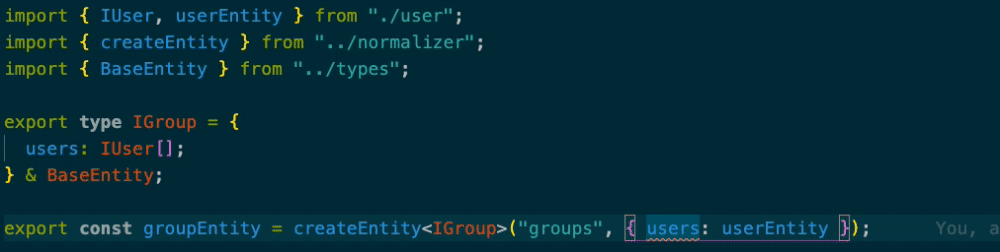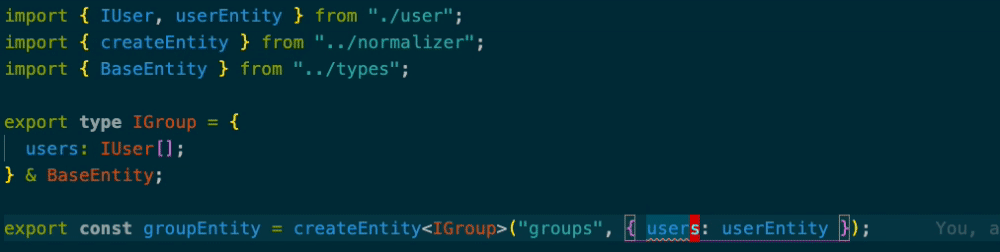
import { IUser, userEntity } from "./user"; import { createEntity } from "../normalizer"; import { BaseEntity } from "../types"; export type IGroup = { users: IUser[]; } & BaseEntity; export const groupEntity = createEntity<IGroup>("groups", { users: [userEntity] });
IUserがentityなのですがcreateEntityの第2引数からusersを消すと型エラーになります。

配列になってないときも型エラーを吐いてくれます。
またsrc/entities/user.tsはIAddressだけがentityでありcomplex, keysが持つ型にはcreateEntityが反応してないことがわかります。
BaseEntityをマージしてないとentityとして認識されないためこの型がentityなのかそうでないのかがしっかり分類できています。

normalizer
与えられたgroupオブジェクトからほしいschemaを導き出せています。resultの型も渡されたgroupオブジェクトは単一なのでstringが返ってきています

denoramlzer
resultは単一のstring, schemaも単一のgroupEntityなので返り値はIGroup | undefined型になっています。

こちらは配列の場合です。同様にうまくいっています。

さいごに
僕はReduxを使う際にnormalizrを多用するのでこのようなヘルパー型を作って楽に開発できるようにしています。entityの作り方に制約をもたせていますが、今のところ特に苦しい場面に出会ってません。(複雑な構造に出会ってないだけかも) なので結構良さそうじゃないかな〜と思っています。できるならライブラリにしたいけど型定義だけのライブラリって作る意味あるんだろうか……。normalizrの機能もかなり制限しちゃってるし…
次はこれをどうReduxに使っているのかを紹介できればなと思います。最後まで見てくださった方ありがとうございました!!
もっとこうしたらいいよという提案はいつでも受け付けています!!